
1. 引言
随着信息技术的发展,审计数据规模也快速增长至TB,PB级,计算机信息化审计[1]也成为必然发展需求。传统的审计数据的采集[2],存储方式是审计单位要求被审计单位导出需要审计数据的压缩文件,如oracle的dmp文件,然后审计单位再将dmp文件导入到自己本地的oracle数据库中查看,存储。具体如图1所示。
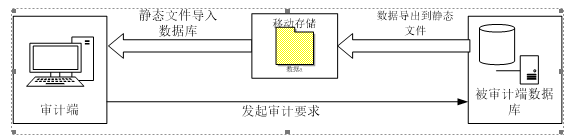
图1
然而,这种数据采集方式有几个缺点:
1) 如果被审计单位数据库很大,数据库导入到静态文件时间会很长,而且静态文件在导入数据库的时间也很长,时间消耗非常大。
2) 如果被审计端提供的静态文件有误或者不完整,审计端需要将静态文件导入后查看才能知道,会花费大量的无用时间。
3) 审计端对于多个被审计端数据都只能导入一个数据库中,数据难于管理。
4) 数据审计修改后,需要再备份困难,需要重新导出静态文件。
5) 审计端数据存储困难,由于多个被审计端数据导入后,数据库庞大,审计端磁盘有限,存储扩展困难。
以上这些缺点说明,现在的计算机审计存在很大问题,没有统一的管理和标准化的存储。数据采集与存储管理花费大量时间,所以,本文介绍一种新的审计数据采集与管理方法——基于kubernetes和glusterfs集群的数据采集存储方案。
2. 基于docker的数据采集方案
随着云计算的快速发展,Docker这一开源的应用容器引擎在云计算中的地位日益突出[3] ,审计活动主要是在审计端还原多个被审计端的数据,然后查询分析,然而一台机器只能同时使用一个数据库,如果需要审 计多个,则需要将多个数据库数据导入一个数据库。这个过程是非常繁琐和耗时的,所以我们使用docker容器引擎,在一台机器运行多个数据库容器,以避免数据库导入过程的时间消耗。具体数据采集过程如图2所示。
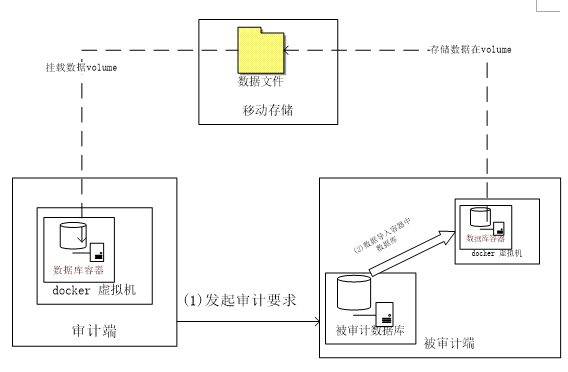
图2
首先审计端发起审计要求,然后被审计端启动一个数据库容器,将本地数据库需要被审计数据导入到数据库容器中,并且数据库容器数据存储在移动存储volume中,然后将volume移动存储中的数据文件拿到审计端,启动一个数据库容器挂载数据文件,就可以查看需要审计的数据。这种数据采集方法,有效的避免了数据库导出静态文件和静态文件再导入数据库的大量时间消耗,同时审计端可以快速的查看被审计数据,避免错误数据文件导入的大量耗时。
由于审计端可能收到很多被审计端提供的数据,所以单台机器可能没有足够的性能运行多个数据库容器,需要用多个机器,但是,人工管理多个容器非常繁琐,并且不能保证安全。所以,为了能够更好的管理多个数据库容器,我们采用一个google的开源容器管理系统kubernetes[4]用于Docker集群的管理。Kubernetes 作为 Docker 生态圈中重要一员,是自动化容器操作的平台,是 Google 开源的容器集群管理系统,提供资源调度、均衡容灾、服务注册、 动态扩缩容等功能套件。利用 Kubernetes 能方便地管理跨机器运行容器化的应用。
审计端使用kubernetes可以自动化的管理多个数据库容器,但是多个数据文件会占据很大的存储空间,同时,审计端要求所以被审计数据都会永久备份在审计端,这就需要一个统一的分布式的存储平台。根据我们的需求:
1) 我们需要存储的是数据库的数据文件,所以都是GB级的大文件;
2) 文件数量不会太大,集群机器不会太多,集群属于小规模;
3) 存储集群需要与kubernetes能够结合,这样可以使kubernetes和存储集群公用机器。
针对以上几个需求,Glusterfs[5] 非常符合需求。Glusterfs是一个分布式的开源存储框架,并且能够与kubernetes的volume结合[6],可以直接作为kubernetes的volume挂载在容器中。
- 当前状态 新增
- 选定优先级 正常
- 指派给 --
- 里程碑 --
- 开始日期 2016-11-26
- 结束日期
- 预计工时(H) 0.00 小时
- 完成度 0%
- 关联Commit 无

