
缺陷 #10938
由ladventure 更新于 2016-12-23 09:22
说 明 书
![]()
一种高可用数据文件分布式存储系统
技术领域
本发明涉及一种基于Glusterfs的分布式存储方法,特别针对于具有高速在线和低速离线备份双存储的以文件夹为整体的数据存储。
背景技术
近年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了传统的计算机存储能力,因此,分布式存储的使用已经越来越普及。
Glusterfs是目前较为成熟的开源分布式存储软件。是一个支持PB级数据存储的无元数据服务器分布式存储系统,支持线性性能扩展,解除对元数据服务器的需求,消除了单点故障了性能瓶颈,真正实现了并行化数据访问。
对于许多大数据应用而言,不仅需要存储数据,还需要快速的切换和访问需要的一部分数据。目前的数据访问瓶颈大部分仍然是磁盘性能,所以,对于高速访问基本采用SSD固态磁盘,但是SSD的代价比普通机械硬盘HDD高许多,而HDD又不能满足高速访问的要求,对于一个拥有海量数据,并且某一时间段内,只需要访问一部分数据的应用而言,全部使用SSD和或者全部使用HDD都是不合理的。对于此类应用,可以构建一个拥有两个数据卷的Glusterfs分布式存储集群,高速访问区用SSD构建高速分布式集群Distributed数据卷,低速数据备份存储区选择HDD构建一个低速廉价分布式集群Distributed数据卷。在未来一段时间内需要频繁访问某个数据时候,可以将数据从HDD数据卷迁移到高速SSD数据卷,数据使用完成后,再将数据从SSD数据卷备份到HDD数据卷。
在集群中,存储的是数据文件夹,其中的文件会分布存储在不同的节点上,这样数据的完整性无法保证,一旦一个节点出现故障,几乎所有的数据文件夹可能都会缺少文件,造成所有的数据文件夹损坏不可使用,这是不能容忍的。但是由于高速数据卷采用SSD做存储介质,代价比较昂贵,而Glusterfs的replicated数据卷的存储利用率非常低,如果用replicated会使存储利用率下降到50%一下,并且一旦两个节点损坏,仍然有丢失所有数据文件夹的可能,所以这样的方案不可行,需要一个替代方案能够满足一下要求:
1. 存储利用率高,由于SSD代价非常高,不能以较大的牺牲存储保证数据安全性。
2. 数据是相对安全的,一个节点的故障不能影响其他节点的数据,高速存储区中的数据在低速廉价存储区都有备份,少量的数据文件夹的丢失可以接受,只需从新从低速存储区再复制一份即可。
3. 不会对数据的访问和存储速度造成较大影响。
目前还没有一个完整的存储方案能够满足以上要求,Glusterfs的是基于弹性Hash算法定位文件,所以文件的分布具有随机性,对于同一个整体数据文件夹中的文件不能保证存储在同一节点上,而这种整体数据文件夹中文件损坏或者丢失一个,整体数据文件夹即损坏。所以,需要一种能够将整体文件夹中的文件存储在同一节点上的高可用分布式存储系统。
发明内容
本发明的目的在于针对现有存储技术的不足,针对整体数据文件夹的高效可靠存储的需求,提出的基于Glusterfs分布式存储的以文件夹为单位分布的高效可靠分布式存储系统。
本发明的技术方案包括两个方面,数据文件夹的存储和集群节点变化的处理负载均衡。
1. 数据文件夹的存储:
步骤1、搭建集群并创建数据卷;
步骤2、在数据卷中创建数据文件夹,具体步骤参见21-24;
步骤3、根据数据文件的文件名计算hash值,并根据父目录的hash分布获取其hash卷;
步骤4、在对应hash卷上创建文件。
2. 子卷变化的数据均衡:
步骤5、查看所有节点可用容量是否超过配额(用户可以设置)。
步骤6、如果没有超过配额,则不处理,如果超过配额,则对于该子卷上的所有数据文件夹重新查找最优子卷,设置数据文件夹hash区间在该节点;
步骤7、对于文件夹中的每个文件,在新节点下创建链接,链接到源文件夹中的每个文件。然后开启数据复制,将源文件复制到新文件夹下。
步骤8、复制完成后,将链接指向新文件,并删除源文件,数据迁移完成,进行下一个数据文件夹迁移,直到容量大于配额设置。
步骤2中所述的具体执行以下步骤:
步骤21、在父目录的所有子卷中创建目录;
步骤22、目录的名如果等于统一存储目录名(用户配置),则进行24;否则,进行23;
步骤23、为每个子卷在该目录上平均分配hash区间,并记录在扩展属性中;
步骤24、寻找最优子卷,将最优子卷hash区间定为最大,其他子卷定为0,并记录在扩展属性中。
采用本发明可以达到以下技术效果:
在基于Glusterfs的分布式文件存储系统中,配置的特定文件名称,该文件名下的所有的文件都会分布在同一子卷上。以保证Glusterfs某个子卷损坏的情况下,其他子卷上的数据文件夹可以正常使用,成功的解决了Glusterfs一个子卷损坏会使所有数据卷中数据失败的问题。同时,由于数据卷子卷的增加可能会引起数据分布的不均衡,新子卷负载教轻,原子卷负载较重,通过数据的重新均衡,以解决子卷数据不均衡问题。
附图说明
图1为本发明数据文件夹的存储的流程图;
图2为本发明数据卷子卷发生变化时候,数据重新均衡的流程图;
具体实施方式
本发明主要针对基于Glusterfs分布式存储系统的数据文件夹的存储。
如图1所示,为本发明数据文件夹的存储流程图,具体执行以下步骤:
步骤 101、搭建一个Glusterfs集群S,并创建包含A,B,C三个子卷的数据卷D,准备在D中存储testFolder数据文件夹;
步骤 102、在所有子卷A,B,C上创建数据目录testFolder;
步骤 103、如果testFolder等于用户配置的特定统一分布目录名称FolderName,则进行105,否则进行104;
步骤 104、在A,B,C上的testFolder平均分配Hash区间。
步骤 105、在A,B,C上的寻找最优的子卷A,将所有Hash区间分配到A上的testFolder,其他B,C上的目录Hash区间为空;
步骤 106、在A,B,C上的testFolder目录扩展属性中记录分配到的Hash区间;
步骤 107、根据数据文件夹中某个文件testFile文件名计算Hash值m;
步骤 108、根据hash值m以及父目录记录的hash区间,确定文件testFile的子卷A;
步骤 109、子卷A的testFolder下面创建文件testFile;
该方案是针对指定数据文件夹中的多个文件需要整体存储,需要更改数据文件夹中的hash区间分配,将Hash区间分配在一个子卷上,保证该数据文件夹下所有文件能够存储在一个子卷上,保持集群的高容错性。
如图2所示,为本发明在数据卷子卷发生变化时候,对于数据的重新均衡流程图,具体执行以下步骤:
步骤 201、数据卷X子卷发生变化,添加子卷D,并启动数据均衡;
步骤 202、扫描X中子卷A的可用容量S;
步骤 203、S是否超过限额Z,如果是执行204,否则执行209;
步骤 204、随机获取存储在子卷A中的一个数据文件夹E;
步骤 205、寻找一个最优子卷D,并将A中E的目录Hash区间设置成0,将D子卷中A中E的hash区间设置成全部;
步骤 206、在D中E目录下创建一个LINKFILE文件,记录E中每个文件目前的子卷A;
步骤 207、将E中的所有文件从A复制到D;
步骤 208、复制完成后,将LINKFILE中记录更改成迁移后的子卷D,然后删除A子卷中E下的文件,重复203;
步骤 209、是否扫描过X中的所有子卷,如果是执行210,数据均衡结束,如果不是将A指向X中的下一个子卷,重复202;
步骤 210 数据均衡结束;
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
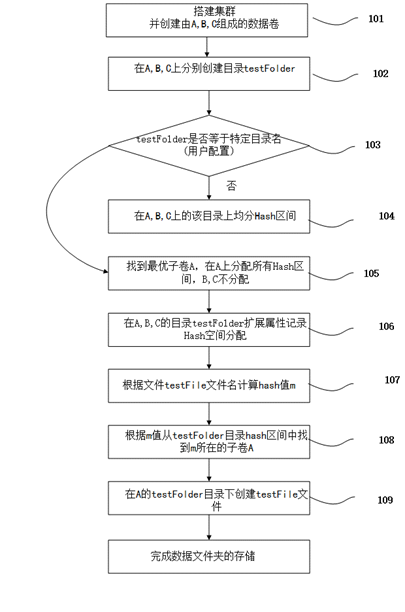
图 1
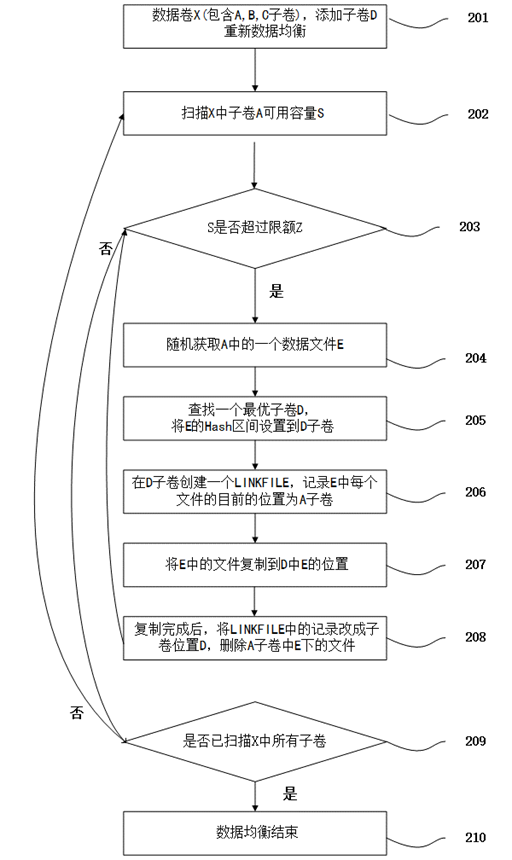
图 2
说 明 书
![]()
一种高可用数据文件分布式存储系统
技术领域
本发明涉及一种基于Glusterfs的分布式存储方法,特别针对于具有高速在线和低速离线备份双存储的以文件夹为整体的数据存储。
背景技术
近年来,随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了传统的计算机存储能力,因此,分布式存储的使用已经越来越普及。
Glusterfs是目前较为成熟的开源分布式存储软件。是一个支持PB级数据存储的无元数据服务器分布式存储系统,支持线性性能扩展,解除对元数据服务器的需求,消除了单点故障了性能瓶颈,真正实现了并行化数据访问。
对于许多大数据应用而言,不仅需要存储数据,还需要快速的切换和访问需要的一部分数据。目前的数据访问瓶颈大部分仍然是磁盘性能,所以,对于高速访问基本采用SSD固态磁盘,但是SSD的代价比普通机械硬盘HDD高许多,而HDD又不能满足高速访问的要求,对于一个拥有海量数据,并且某一时间段内,只需要访问一部分数据的应用而言,全部使用SSD和或者全部使用HDD都是不合理的。对于此类应用,可以构建一个拥有两个数据卷的Glusterfs分布式存储集群,高速访问区用SSD构建高速分布式集群Distributed数据卷,低速数据备份存储区选择HDD构建一个低速廉价分布式集群Distributed数据卷。在未来一段时间内需要频繁访问某个数据时候,可以将数据从HDD数据卷迁移到高速SSD数据卷,数据使用完成后,再将数据从SSD数据卷备份到HDD数据卷。
在集群中,存储的是数据文件夹,其中的文件会分布存储在不同的节点上,这样数据的完整性无法保证,一旦一个节点出现故障,几乎所有的数据文件夹可能都会缺少文件,造成所有的数据文件夹损坏不可使用,这是不能容忍的。但是由于高速数据卷采用SSD做存储介质,代价比较昂贵,而Glusterfs的replicated数据卷的存储利用率非常低,如果用replicated会使存储利用率下降到50%一下,并且一旦两个节点损坏,仍然有丢失所有数据文件夹的可能,所以这样的方案不可行,需要一个替代方案能够满足一下要求:
1. 存储利用率高,由于SSD代价非常高,不能以较大的牺牲存储保证数据安全性。
2. 数据是相对安全的,一个节点的故障不能影响其他节点的数据,高速存储区中的数据在低速廉价存储区都有备份,少量的数据文件夹的丢失可以接受,只需从新从低速存储区再复制一份即可。
3. 不会对数据的访问和存储速度造成较大影响。
目前还没有一个完整的存储方案能够满足以上要求,Glusterfs的是基于弹性Hash算法定位文件,所以文件的分布具有随机性,对于同一个整体数据文件夹中的文件不能保证存储在同一节点上,而这种整体数据文件夹中文件损坏或者丢失一个,整体数据文件夹即损坏。所以,需要一种能够将整体文件夹中的文件存储在同一节点上的高可用分布式存储系统。
发明内容
本发明的目的在于针对现有存储技术的不足,针对整体数据文件夹的高效可靠存储的需求,提出的基于Glusterfs分布式存储的以文件夹为单位分布的高效可靠分布式存储系统。
本发明的技术方案包括两个方面,数据文件夹的存储和集群节点变化的处理负载均衡。
1. 数据文件夹的存储:
步骤1、搭建集群并创建数据卷;
步骤2、在数据卷中创建数据文件夹,具体步骤参见21-24;
步骤3、根据数据文件的文件名计算hash值,并根据父目录的hash分布获取其hash卷;
步骤4、在对应hash卷上创建文件。
2. 子卷变化的数据均衡:
步骤5、查看所有节点可用容量是否超过配额(用户可以设置)。
步骤6、如果没有超过配额,则不处理,如果超过配额,则对于该子卷上的所有数据文件夹重新查找最优子卷,设置数据文件夹hash区间在该节点;
步骤7、对于文件夹中的每个文件,在新节点下创建链接,链接到源文件夹中的每个文件。然后开启数据复制,将源文件复制到新文件夹下。
步骤8、复制完成后,将链接指向新文件,并删除源文件,数据迁移完成,进行下一个数据文件夹迁移,直到容量大于配额设置。
步骤2中所述的具体执行以下步骤:
步骤21、在父目录的所有子卷中创建目录;
步骤22、目录的名如果等于统一存储目录名(用户配置),则进行24;否则,进行23;
步骤23、为每个子卷在该目录上平均分配hash区间,并记录在扩展属性中;
步骤24、寻找最优子卷,将最优子卷hash区间定为最大,其他子卷定为0,并记录在扩展属性中。
采用本发明可以达到以下技术效果:
在基于Glusterfs的分布式文件存储系统中,配置的特定文件名称,该文件名下的所有的文件都会分布在同一子卷上。以保证Glusterfs某个子卷损坏的情况下,其他子卷上的数据文件夹可以正常使用,成功的解决了Glusterfs一个子卷损坏会使所有数据卷中数据失败的问题。同时,由于数据卷子卷的增加可能会引起数据分布的不均衡,新子卷负载教轻,原子卷负载较重,通过数据的重新均衡,以解决子卷数据不均衡问题。
附图说明
图1为本发明数据文件夹的存储的流程图;
图2为本发明数据卷子卷发生变化时候,数据重新均衡的流程图;
具体实施方式
本发明主要针对基于Glusterfs分布式存储系统的数据文件夹的存储。
如图1所示,为本发明数据文件夹的存储流程图,具体执行以下步骤:
步骤 101、搭建一个Glusterfs集群S,并创建包含A,B,C三个子卷的数据卷D,准备在D中存储testFolder数据文件夹;
步骤 102、在所有子卷A,B,C上创建数据目录testFolder;
步骤 103、如果testFolder等于用户配置的特定统一分布目录名称FolderName,则进行105,否则进行104;
步骤 104、在A,B,C上的testFolder平均分配Hash区间。
步骤 105、在A,B,C上的寻找最优的子卷A,将所有Hash区间分配到A上的testFolder,其他B,C上的目录Hash区间为空;
步骤 106、在A,B,C上的testFolder目录扩展属性中记录分配到的Hash区间;
步骤 107、根据数据文件夹中某个文件testFile文件名计算Hash值m;
步骤 108、根据hash值m以及父目录记录的hash区间,确定文件testFile的子卷A;
步骤 109、子卷A的testFolder下面创建文件testFile;
该方案是针对指定数据文件夹中的多个文件需要整体存储,需要更改数据文件夹中的hash区间分配,将Hash区间分配在一个子卷上,保证该数据文件夹下所有文件能够存储在一个子卷上,保持集群的高容错性。
如图2所示,为本发明在数据卷子卷发生变化时候,对于数据的重新均衡流程图,具体执行以下步骤:
步骤 201、数据卷X子卷发生变化,添加子卷D,并启动数据均衡;
步骤 202、扫描X中子卷A的可用容量S;
步骤 203、S是否超过限额Z,如果是执行204,否则执行209;
步骤 204、随机获取存储在子卷A中的一个数据文件夹E;
步骤 205、寻找一个最优子卷D,并将A中E的目录Hash区间设置成0,将D子卷中A中E的hash区间设置成全部;
步骤 206、在D中E目录下创建一个LINKFILE文件,记录E中每个文件目前的子卷A;
步骤 207、将E中的所有文件从A复制到D;
步骤 208、复制完成后,将LINKFILE中记录更改成迁移后的子卷D,然后删除A子卷中E下的文件,重复203;
步骤 209、是否扫描过X中的所有子卷,如果是执行210,数据均衡结束,如果不是将A指向X中的下一个子卷,重复202;
步骤 210 数据均衡结束;
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
图 1
图 2

