
缺陷 #11048
由ladventure 更新于 2016-12-26 23:39
之前版本:
论文基于数据在不同volume上面的迁移后校验为基础,设计了三种方案:
- 迁移前计算源文件MD5,迁移完成后计算目的文件MD5,然后校验;
- 计算源文件MD5,迁移中同时计算目的文件的MD5值,完成迁移后校验;
- 设计流水线的方式计算源文件MD5和迁移并计算目的文件MD5,完成后校验。
对于三种方式,分别实验,分别对于低速数据卷 L 到 高速数据卷H,以及H>L, H>H,L>L
对于不同大小文件效率:
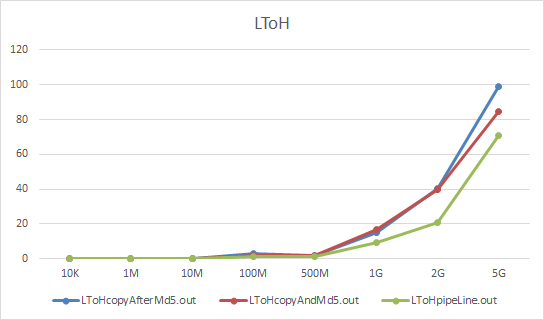
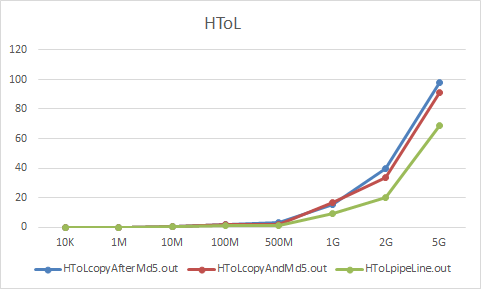
以及其他两个数据,变化趋势基本相同。流水线方式对于性能有较好提升。
流水线方式的优化:
流水线方式复制文件和获取MD5值方式对于流水线的粒度和流水线缓冲队列长度优化数据:
当前版本:
论文基于数据在不同volume上面的迁移后校验为基础,设计了三种方案:
- 迁移前计算源文件MD5,迁移完成后计算目的文件MD5,然后校验;
- 计算源文件MD5,迁移中同时计算目的文件的MD5值,完成迁移后校验;
- 设计流水线的方式计算源文件MD5和迁移并计算目的文件MD5,完成后校验。
对于三种方式,分别实验,分别对于低速数据卷 L 到 高速数据卷H,以及H>L, H>H,L>L
对于不同大小文件效率:
以及其他两个数据,变化趋势基本相同。流水线方式对于性能有较好提升。
流水线方式的优化:
流水线方式复制文件和获取MD5值方式对于流水线的粒度和流水线缓冲队列长度优化数据:
这是LToH的优化数据
其中行表示缓存粒度,列表示缓存队列长度,由这数据可以得出流水线的最优参数。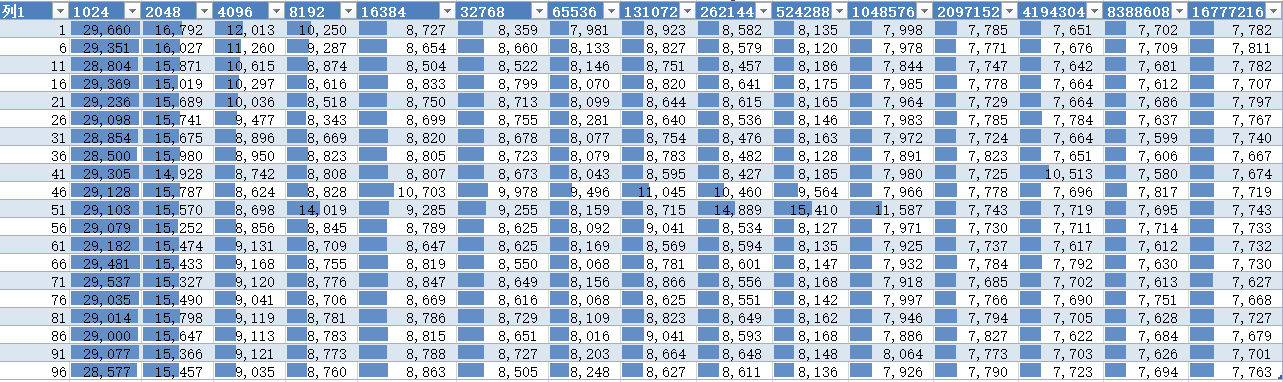
还有对于glusterfs io/cache使用对效率的影响:主要是获取源文件MD5值的影响,因为获取源文件MD5值时候已经读取过源文件了,此时如果缓存大小合适,则缓存命中,读取速度回大幅度提升,(用于高速网络),如L>L 的流水线模式比较:

显然对于第一次读取有一定的效率下降,但第二次读取效率提升明显,总的效率有一定提升

