
项目简介
Sonar是神器,围绕代码质量管理的神器。她几乎支持了你所能想到的一切代 码质量问题:从静态分析到动态分析(单元测试)、从系统分析到人工评审、从 历史分析到现在的版本分析、从Web客户端到Eclipse插件、从本地分析到远程分 析、从集成其他代码分析插件(FindBugs、PMD等)到作为插件被CI持续集成、 从邮件通信到任务平台交换(如JIRA)、从Web接口到插件开发,这些不一而足, 再加上Sonar的开源特征、神一般的操作界面,没有人可以拒绝她的美丽。

《A Brief Guide to Researching and Writing for CSEE&T (Conference on Software Engineering Education and Training)》
这篇文章综述了软件工程教育类文章的接受标准、研究方法、文章分类以及研究建议。下面对文章分类及其写法做个小结:
一、文章分类
1. 实验描述类:
这类文章一般是对学生做受控实验,来回答某些特定的研究问题。这类文章需要描述实验假设、因变量和自变量、研究对象、实验方法、分析方法、结论以及对结论的引申;
2. 创新教育方法类:(持续检查这篇文章应该属于这类)
这类文章一般以案例研究的形式,来描述老师在某个特定领域创新教学的经验。这类文章应该详细介绍创新方法与其他方法的优点和不足,一般通过定性+定量的方式来评估,在这篇文章中定性方法包括调查问卷和访谈,定量方法包括数据分析和代码质量测试
3. 经验描述类:
描述参与教育活动中的经验。这类文章要避免写成“报告”,一般会介绍经验、过程、决策等。
二、需要注意的地方
1. 调查问卷:保证问题、选项的无二义性;
2. 基于教室的研究:一种是基于将一种方法应用在教学中,比较前后的效果,这篇文章应该属于这类;另一种是将学生分成两拨,比较效果,这种方法可以用在现在正在进行的众包方法应用在教学的研究中,这种方法要考虑研究对象本身的属性,如编程经历。

1. 过程:分别在实施持续检查(Continuous Inspection)前、中、后进行了代码质量测试;
2. 测试内容:每次测试8道题,均有质量问题,学生需要写明质量问题所在的代码行号和出错原因,问题从SonarQube的质量规则中选择设置,每次测试都会覆盖相同类型的3道题;
3. 测试结果:
下图是学生3次代码质量测试答对题目的统计:

可以看到学生答对的题目数有较显著的提高。
下图是3道同类别题的答对人数:

可以虽然看到同学对close file类和if case类问题的理解度随有所增加,但提高程度不大,可能的原因是学生平时遇到这类问题不多,可以从这方面提出一些经验建议,以全面提高学生的编程质量。
下一步计划深入挖掘学生的持续检查过程数据。

一、根据ISO/9126,软件质量包括:
外部质量:满足软件功能性需求的好坏程度,如正确性、易用性、完整性等
内部质量:代码的重要属性,如可维护性、可理解性、可修改性等
传统的保证代码质量的方法是定期代码审查(Punctual Audits),即指定专门的代码质量审查人员定期做代码审查(如下图),Trustie工程组好像是采用这种方式。

然而这种方式存在一些弊端:如下图
图片 2.png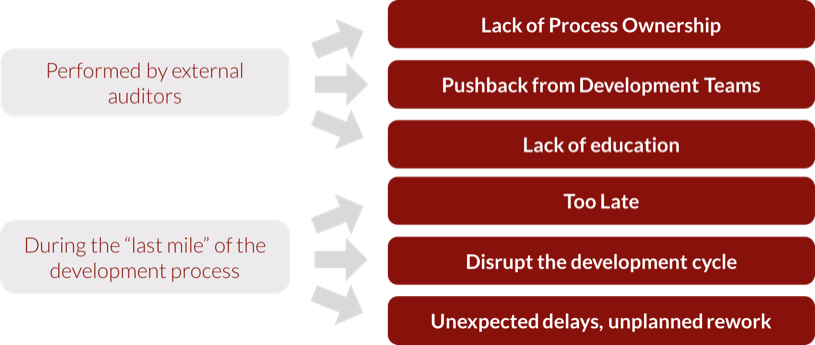
这些弊端促成Continous Inspection这种新的质量保证泛型的出现,为了克服传统质量保证泛型的弊端,Continuous Inspection的核心理念是“尽早地发现解决质量问题,当修复工作还容易时;让所有利益相关者参与到质量保证的工作环节中去”,重要的原则如下图所示:

如下图所示,Continuous Inspection也是软件开发需求的推动:
 如下图所示,Continuous Inspection与Continuous Integration相结合:
如下图所示,Continuous Inspection与Continuous Integration相结合:

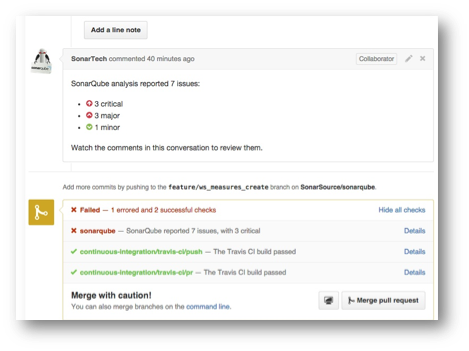

一、实验思路
分别对bug_intro的commit与bug_fix的commit进行soanr扫描,分别得到对应的sonar的issue结果表,对每条引入buggy的line与产生sonar_issue的line进行匹配,如果行数重合,那就说明这个文件中bug与sonar_issue发生了同现的关系,在bug_fix的commit中再用sonar进行扫描如果发现sonar_issue与bug一起消失掉了,我们把这种现象认为是代码质量与bug是存在关系的
二、初步试验结果
目前主要是java跑了五个项目,python跑了四个项目,基于目前的结果我们发现:
1)java 项目一共有1411个bug,其中随着和bug一起消失的sonar_issue有275个,比例达到了20%,其中对这种issue进行分类排序后发现如下现象:
1、convention 193(代码编码习惯:比如命名规则,驼峰状的命名规则)
2、brain-overload 181(方法的时间复杂度)
3、design 175(代码的设计:主要是一些类的设计)
4、pitfall 97(代码逻辑缺陷:比如空指针错误)
5、error-handing,security 95(代码中的异常处理等)
java项目的sonar中的代码规则比较多与详细,基于如此的结果可以发现代码复杂度过高,逻辑设计错误,异常处理不正确往往与bug同时出现
2)python项目中主要是有2342个bug出现,bug与sonar_issue一起消失的数量有328个,比例达到了14%,其中对这些issue分类排序发现以下结果:
1、brain-overload 210(方法的时间复杂度)
2、convention 110 (代码编码规范)
3、performance 87 ()
4、confusing 85(代码方法,变量命名不能混淆)
5、obsolete 52
基于以上的数据可以发现,方法复杂度过高与bug 同现的次数比较大,但由于soanr对python语言的支持不是那么好,所以现有的数据比较少
三、意见
这两天分别听取了王涛师兄与余跃师兄的意见,还有很多需要改进的地方,比如实验的方法,对具体代码行数的sonar issue判断是否准确,还有issue 与buggy中的关系到底如何定义,最后需要对bug分类来验证这个bug是否真的与sonar_issue相关等等
四、后序展望
目前的展望还是要对实验进行改进,我觉得目标应该是发现一种关系当某些issue被sonar扫描出来是,需要引起开发者注意,因为这种issue会有比较大的可能性去引发bug,现在主要的结果还是发现了一些issue与bug的同现概率比较大,具体的下一步思路,还需要和师兄们多多讨论
一、实验思路
分别对bug_intro的commit与bug_fix的commit进行soanr扫描,分别得到对应的sonar的issue结果表,对每条引入buggy的line与产生sonar_issue的line进行匹配,如果行数重合,那就说明这个文件中bug与sonar_issue发生了同现的关系,在bug_fix的commit中再用sonar进行扫描如果发现sonar_issue与bug一起消失掉了,我们把这种现象认为是代码质量与bug是存在关系的
二、初步试验结果
目前主要是java跑了五个项目,python跑了四个项目,基于目前的结果我们发现:
1)java 项目一共有1411个bug,其中随着和bug一起消失的sonar_issue有275个,比例达到了20%,其中对这种issue进行分类排序后发现如下现象:
1、convention 193(代码编码习惯:比如命名规则,驼峰状的命名规则)
2、brain-overload 181(方法的时间复杂度)
3、design 175(代码的设计:主要是一些类的设计)
4、pitfall 97(代码逻辑缺陷:比如空指针错误)
5、error-handing,security 95(代码中的异常处理等)
java项目的sonar中的代码规则比较多与详细,基于如此的结果可以发现代码复杂度过高,逻辑设计错误,异常处理不正确往往与bug同时出现
2)python项目中主要是有2342个bug出现,bug与sonar_issue一起消失的数量有328个,比例达到了14%,其中对这些issue分类排序发现以下结果:
1、brain-overload 210(方法的时间复杂度)
2、convention 110 (代码编码规范)
3、performance 87 ()
4、confusing 85(代码方法,变量命名不能混淆)
5、obsolete 52
基于以上的数据可以发现,方法复杂度过高与bug 同现的次数比较大,但由于soanr对python语言的支持不是那么好,所以现有的数据比较少
三、意见
这两天分别听取了王涛师兄与余跃师兄的意见,还有很多需要改进的地方,比如实验的方法,对具体代码行数的sonar issue判断是否准确,还有issue 与buggy中的关系到底如何定义,最后需要对bug分类来验证这个bug是否真的与sonar_issue相关等等
四、后序展望
目前的展望还是要对实验进行改进,我觉得目标应该是发现一种关系当某些issue被sonar扫描出来是,需要引起开发者注意,因为这种issue会有比较大的可能性去引发bug,现在主要的结果还是发现了一些issue与bug的同现概率比较大,具体的下一步思路,还需要和师兄们多多讨论
一、度量的提出:
对之前的GQM模型改进,从开发者的贡献代码量、开发质量和社交活跃度三个方面评价,具体如下:

CCGN(changed lines of code):变更的代码行数。
CMT(number of commits):提交代码的次数。
IRPT(number of reports):提交的问题报告(issue report)的数量。
GBG(generated bugs):平均每行代码引入的缺陷数。
GQI(generated quality issues):平均每行引入的代码质量问题数。
CMNT(number of comments):评论的数量,包括issue、pull request和commit的评论。
AAT(average active time):平均活跃时间,即计算某个开发者相邻社交活动间隔时间的平均值。
二、实验进展
目前分析了python排名前五的三个项目(httpie,flask,requests)的开发者贡献度的指标,分析结果在附件中,目前粗略分析了开发者开发质量的两个指标GBG和GQI的相关关系,结果如下:
对三个项目分别分析:
httpie:

pearson相关系数:-0.01115682
httpie:

pearson相关系数为-0.01006093

pearson相关系数为0.268149
从这三个项目分别的分析结果可以看出,开发者在开发过程中引入的代码质量问题与引入的bug数的相关性很小,也就是说,开发者的开发水平较差不一定引入的bug就多。这与常识不太相符。
将三个项目数据合在一起做pearson相关,也得到一样的结果:
pearson相关系数为:0.1419347
下一步打算进一步分析其他指标的关系,尤其对个体开发者,以时间为维度分析其开发质量的变化

目前一直在安装愉悦师兄与路遥师兄的指示下研究算法、做实验,在尹老师、王涛师兄的指导下一直在研究对项目代码质量的评估。
进展如下:
1、阅读了师兄们给的论文,首先确定了寻找在项目开发中的bug_introduced 与 bug_fix的相应的commit,算法的流程主要安装路遥师兄给的论文中的模型来做实验,同时由于愉悦师兄已经在这个方面有过很好地基础,我们在理解吃透余悦师兄的代码基础上,继续做实验,算法的流程图如下:

2、基于第一步的实验结果,我们继续提出了运用sonar来具体扫描bug_introduced_commit 与 bug_fixed_commit相应的文件,寻找其中具体的代码行的issue(代码质量缺陷)以此来推断sonar_isssue与相应的bug之间的关系,在上一周我已基本实现代码(python),但是由于时间比较仓促,代码还是有很多bug,上周末我花了两天的时间重构了代码,目前已经将代码上传到trustie,让师兄进行审阅,对实验结果初步的分析后发现,代码的方法复杂度过高,运用switch 等代码会导致比较多的bug。
问题与展望:
1、我打算将代码质量的优化还需要进行,目前在用sonar扫描具体文件时,花费的时间还是太多,整体的时间还是不够理想(目前的实验只是初步对一个项目进行了测试,如果是上百个项目的数据量可能时间不是很理想)
2、在得到sonar的具体的代码缺陷与用git得到具体的bug后,我对下一步的研究还是有点迷茫,打算还是和余悦、路遥师兄继续多交流。
3、这周的任务还是要先将目前的实验结果都跑出来,在继续分析

同伴(peer)的定义:若一个用户@了另一用户,则两人在该评论记录中组成同伴;
如上图,总结用户评论有以下几种模式,其回复延迟时间计算如下:
1. 没有@符号,且第一次评论,且没有同伴:计算该comment与第一条comment的时间间隔,如c2
2. 没有@符号,非第一次评论,且没有同伴:计算该comment与最近一条comment的时间间隔, 如c7
3. 没有@符号或者有@符号,有同伴:计算该comment与最近一条同伴的comment的时间间隔,如c5,c6
4. 有@符号,第一次评论,且@之前没同伴,且@的对象未出现过:计算该comment与第一条comment的时间间隔,如c4
5. 有@符号,第一次回复,且之前没有同伴,且@的对象之前出现过:计算该comment与@对象的最后一次评论的时间间隔,如c3
通过分析数据,我们发现github与git用户匹配问题有如下几种:
- 一些人只通过git上上传代码,在github上没有任何活动,这类人一般是项目的核心成员,在计算人员贡献时,不予以考虑,因为这些人关于在github中的活动度量都为0,且我们度量的是开源社区中的人员贡献
- 一些人(很大一部分)只在github有活动,没提交过代码,这类人一般是用户,在计算人员贡献时,予以考虑
- git和github用户关联关联问题:git和github用户使用不同的账号或邮箱登陆,对此我们用一下规则关联用户
- 用邮箱匹配,若邮箱相同,则认为是同一用户
- 用姓名匹配,github和git中都有真实姓名的属性,若两人的姓名相同,则认为是同一用户
- 用commits表中的commit[author]与committer关联,认为是同一用户,如下图,commit的Chris Jenkins与committer中的chrisjenx是同一用户


